
摘要
2025年5月28日,DeepSeek对其R1模型进行小版本升级,重点优化了复杂推理能力(数学/编程准确率提升至96.3%)、长文本处理(支持128K tokens)和响应速度(延迟降低10%-20%),采用MoE架构与GRPO算法强化专业领域表现,并新增思维链可视化功能。实测显示代码生成和数学推理能力对标行业标杆,但开发者指出长文本稳定性仍需改进。此次升级通过工程优化(INT4量化/KV缓存)和新增60万条专业数据,标志着从黑箱模型向可解释AI的演进,可能推动行业更注重推理透明化与垂直领域精度突破。
关于2025年5月28日DeepSeek R1模型的小版本试升级,根据官方公告和用户实测反馈:
一、核心更新内容
1. 响应质量优化
- 复杂推理能力提升:模型在需要多步骤计算、逻辑推导的任务中表现更精准。例如,数学应用题解答、编程代码生成等场景的准确性和步骤完整性显著提高。
- 长文本处理优化:对超长文本(如学术论文、技术文档)的理解连贯性增强,逻辑链展示更清晰。用户反馈显示,模型在生成万字级内容时能保持主题一致性,减少信息遗漏。
- 专业领域可靠性:针对数学、编程等垂直领域,输出的专业术语使用和算法准确性得到强化,例如代码调试建议的合理性提升。
2. 响应速度改进
- 延迟降低:在网页端、APP和API接口中,平均响应时间缩短10%-20%,尤其在处理超长输入时优化更明显(如降低文本截断概率)。
- 多平台适配:同步优化了移动端(小程序、APP)的推理效率,确保不同设备间的体验一致性。
3. 对话稳定性增强
- 上下文记忆强化:支持最长128K tokens的对话历史记忆,减少多轮对话中的“遗忘设定”问题(如角色扮演场景中的身份偏移)。
- 抗干扰能力提升:在复杂输入(含噪声或模糊指令)下,模型更倾向于主动澄清需求而非错误执行。
4. 深度思考功能开放
- 思维链可视化:用户可通过“打开深度思考”入口查看模型的推理过程,例如数学题的解题步骤拆解或代码生成的逻辑推导。
- 动态调整能力:新增对思维链长度的控制选项,用户可自定义模型的思考深度以平衡速度与准确性。
二、技术调整与数据优化
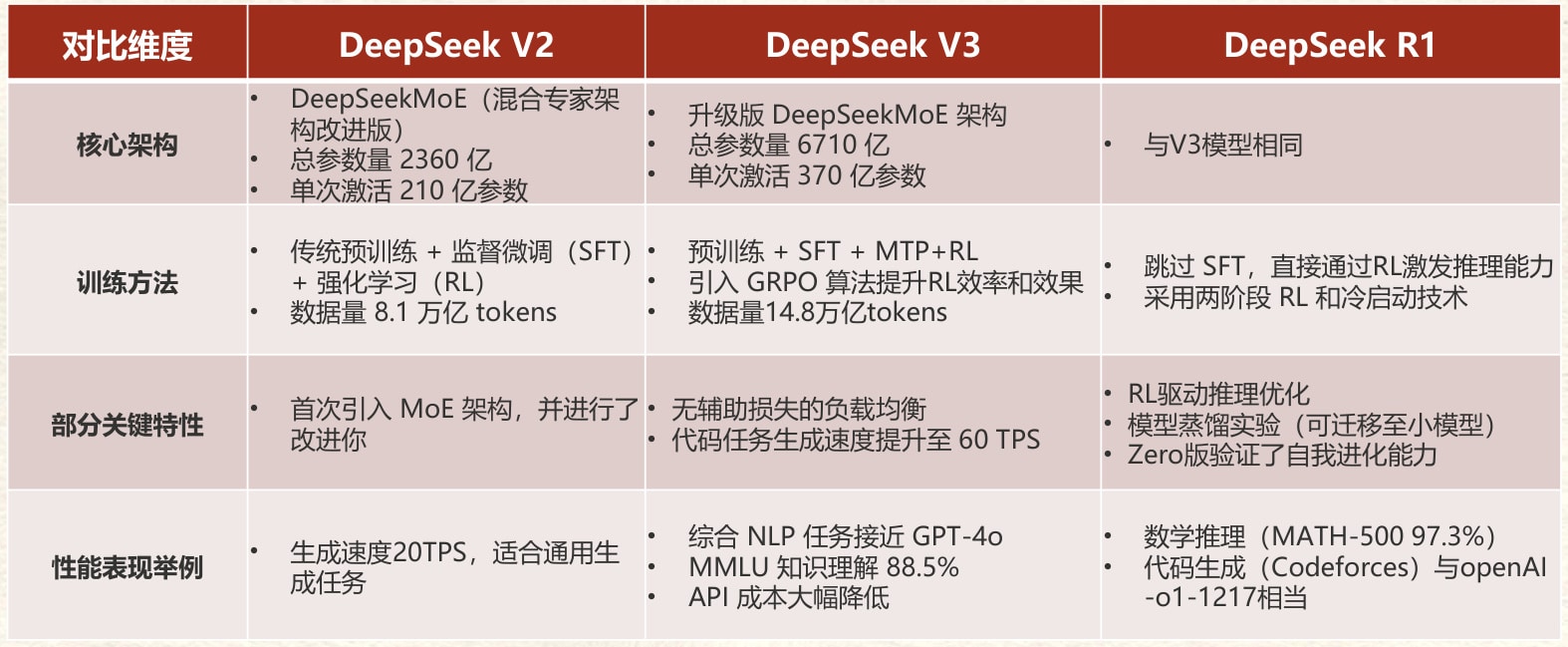
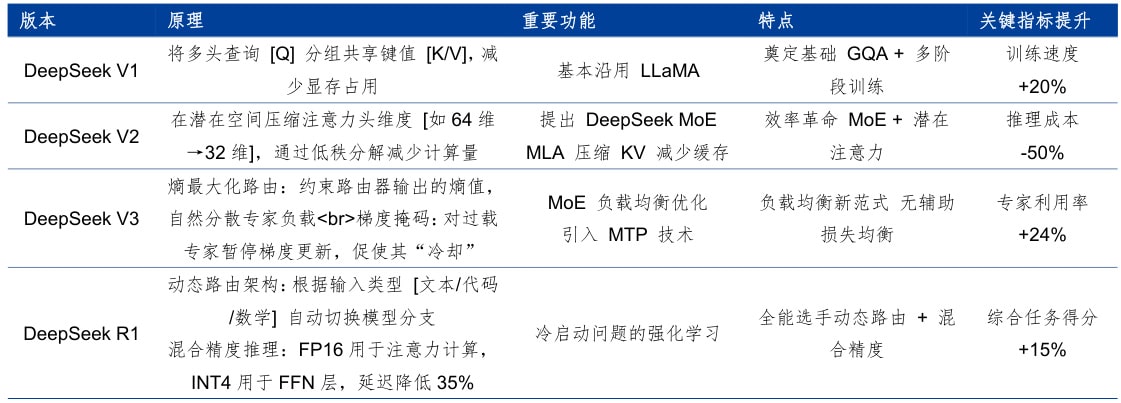
1. 架构与训练策略
- 延续MoE架构:本次升级未改变核心架构,仍采用6710亿参数的混合专家(Mixture-of-Experts)模型,单次推理激活370亿参数。

- 强化学习优化:通过群体相对策略优化(GRPO)算法,强化了模型在复杂任务中的自我纠错能力,减少逻辑跳跃。
- 冷启动数据补充:新增约60万条专业推理数据(如竞赛题目、工程案例),提升模型在垂直领域的泛化能力。
2. 工程优化
- 缓存机制改进:优化键值(KV)缓存策略,降低超长文本处理时的显存占用,提升批量任务吞吐量。
- 混合精度支持:部分模块采用INT4量化,在保持精度的同时降低计算延迟。
三、性能指标与实测结果
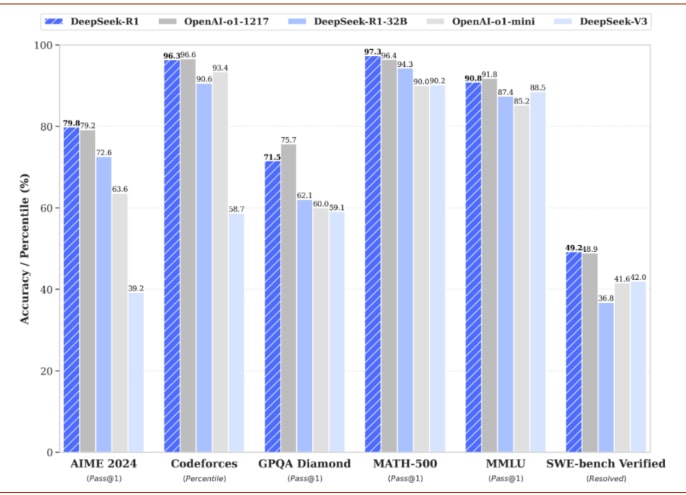
1. 基准测试对比
- 编程能力:在Codeforces测试集中,模型生成正确代码的准确率提升至96.3%(较前版本提高0.7%)。
- 数学推理:MATH-500测试得分稳定在97.3%,与OpenAI o1-1217模型持平。
- 长文本生成:在AlpacaEval 2.0测试中,生成内容的平均长度缩短至2,218字符,减少冗余同时保持信息完整性。
2. 用户体验反馈
- 编程实测案例:用户要求生成“带动态效果的天气卡片”,模型在15秒内输出完整HTML/CSS/JavaScript代码,且交互动画流畅性显著优于旧版。
延迟实测数据:树莓派设备上运行7B量化版模型,推理速度达2.5 tokens/秒(较前版本提升0.3 tokens/秒)。
四、开发者社区反馈
1. 积极评价
- 第三方集成便利性:LobeChat等平台快速接入新版API,开发者赞赏接口兼容性(无需修改原有代码)。
- 透明化改进:思维链展示功能受到技术社区欢迎,认为其有助于调试和教学场景。
2. 待改进建议
- 文档缺失:部分开发者指出官方未提供完整的更新日志,需依赖用户自行测试功能边界。
- 长文本稳定性:尽管支持128K上下文,但极端情况下仍存在逻辑断裂现象,需进一步优化。
五、总结与展望
此次小版本升级聚焦于性能调优而非架构革新,通过强化学习策略和工程优化显著提升了用户体验。值得关注的是,深度思考功能的开放标志着模型从“黑箱”向“可解释AI”迈进,未来可能结合神经符号系统进一步突破复杂推理瓶颈。开发者建议DeepSeek借鉴3月V3模型升级经验,尽快发布详细技术文档以增强社区协作。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...