
Apple AI
从设备端神经引擎到伦理化AI设计,深度揭秘苹果如何以20亿设备为基盘,在生成式AI浪潮中走出「第三条道路」
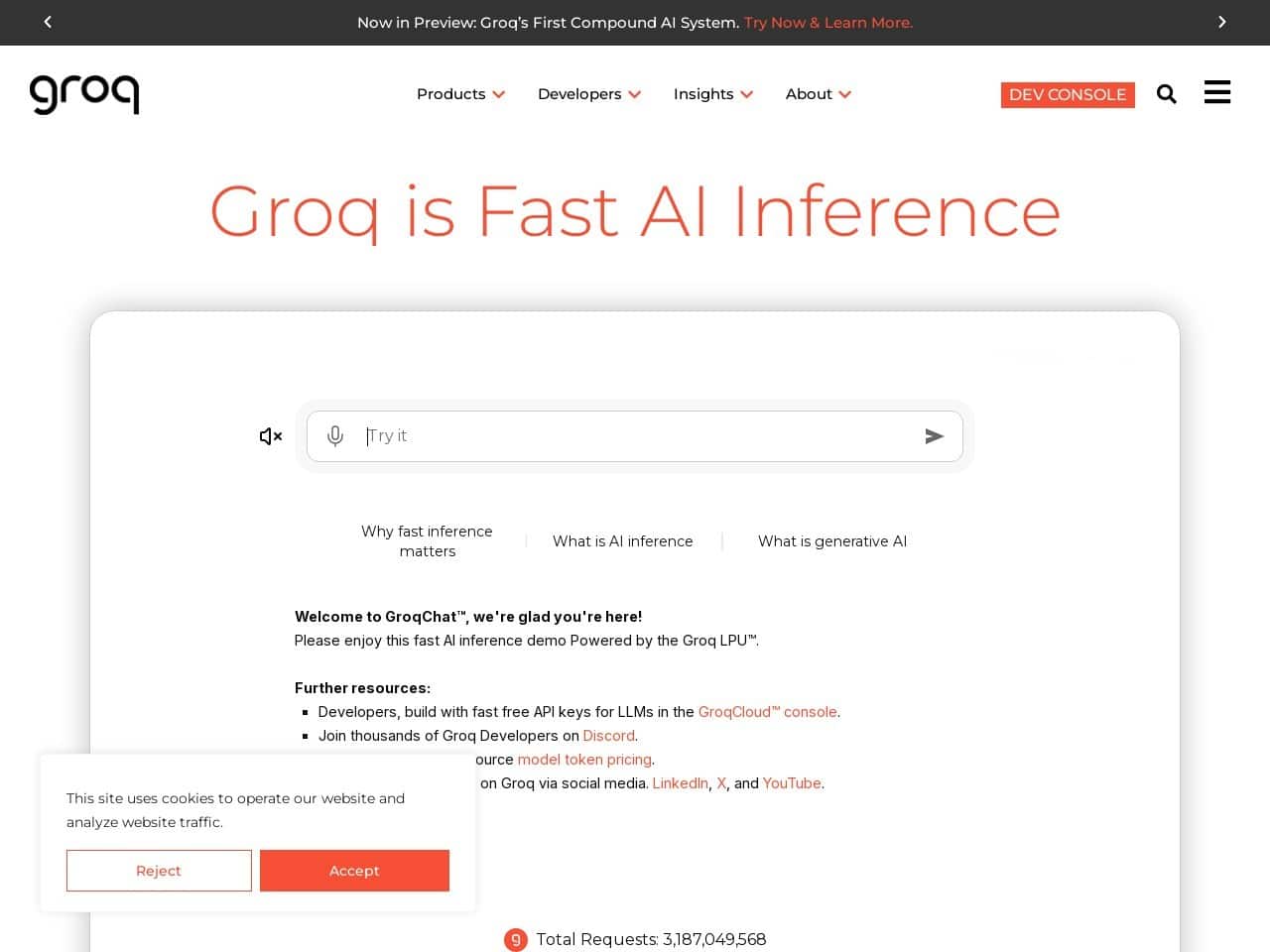
Groq凭借自研LPU架构实现AI推理速度革命,为金融、客服、工业设计等领域提供毫秒级响应解决方案,重新定义实时计算边界
颠覆AI推理的闪电侠:Groq如何用LPU改写游戏规则?
当全球科技巨头还在GPU的赛道上你追我赶时,这家硅谷新贵已悄然开辟新战场。由“TPU之父”Jonathan Ross创立的Groq,正用自研的 语言处理单元(LPU) 掀起AI推理速度革命——每秒处理700个令牌的狂暴性能,直接把传统GPU甩出十条街。
Groq的LPU就像个精准的瑞士钟表匠,用确定性流式架构重构计算逻辑。抛弃传统多核设计的混沌调度,单芯片230MB SRAM构成的高速跑道,让数据无需在内存间折返跑。这波操作不仅实现5-10倍于NVIDIA H100的推理速度,更将能耗砍至对手的1/3。
| 性能指标 | Groq LPU | NVIDIA H100 |
|---|---|---|
| 令牌处理速度 | 700/秒 | 70-140/秒 |
| 硬件成本/Tokens | $0.27/百万 | $1.89/百万 |
| 典型功耗 | 200W | 700W |
数据来源:GroqCloud定价文档及第三方测试报告
Groq左手握着GroqCloud这把利剑,用$0.27/百万tokens的激进定价横扫API市场;右手为车企、金融机构等大客户定制本地化方案。这种“云服务引流,硬件变现”的打法,短短16周就圈粉28万开发者,连Meta的Llama3都跑来站台。
杀手级应用场景:
尽管LPU在单序列推理场景独孤求败,但面对长上下文处理仍显吃力。更棘手的是,其完全定制化的架构就像把双刃剑——14nm制程虽降低成本,却需专用编译器才能发挥威力。有分析师算过笔账:想要盈亏平衡,Groq得把现有速度再提7倍!
“Not only does Groq deliver speed, but it also slashes energy consumption,” 某AI实验室负责人感叹,”But integrating it requires rewriting half our codebase.”
正如半导体教父吉姆·凯勒预言:“未来五年,AI芯片将分化成训练巨兽和推理飞刀。”Groq显然押注后者,但想从NVIDIA碗里抢肉吃,光靠速度还不够——得把开发者生态建成护城河。








识别右侧二维码,进入阅读全文