
Kyutai
法国的一家AI技术发展的非盈利研究机构
Cerebras Systems凭借革命性晶圆级引擎技术,以单片芯片重塑AI计算边界,引领超大规模模型训练与推理效率的新纪元!
要说AI芯片界的”异类”,Cerebras Systems绝对当仁不让!这家2016年成立于硅谷森尼韦尔的硬核科技公司,由SeaMicro创始人Andrew Feldman领衔,一出手就打破了”小芯片堆叠”的行业惯性。他们的核心理念简单粗暴: 与其拼接成百上千个小芯片,不如直接造一块巨型晶圆级引擎(Wafer-Scale Engine, WSE) 。这种”大就是美”的哲学,让Cerebras的WSE-3芯片面积达到46225平方毫米——足足是英伟达H100的57倍,集成了4万亿晶体管和90万AI核心,堪称半导体工业的”珠穆朗玛峰”!
核心创新点解析:
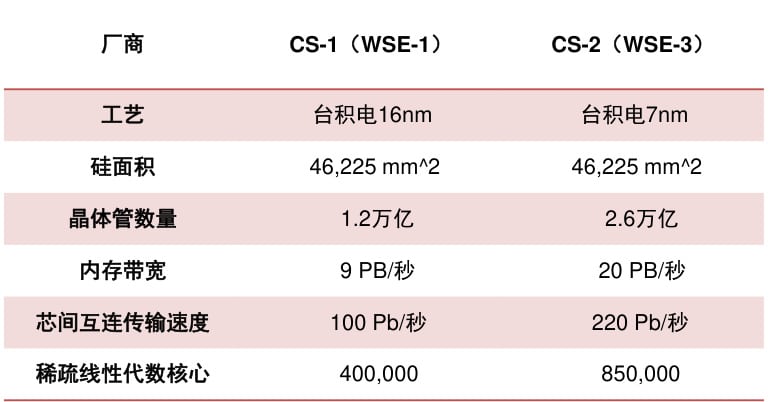
产品迭代对比表:
| 参数 | CS-1 (2019) | CS-2 (2022) | CS-3 (2024) |
|---|---|---|---|
| 制程工艺 | 16nm | 7nm | 5nm |
| 晶体管数量 | 1.2万亿 | 2.6万亿 | 4万亿 |
| 核心数量 | 40万 | 85万 | 90万 |
| 片上内存 | 18GB | 40GB | 44GB |
| 峰值算力 | 9 PFLOPS | 20 PFLOPS | 125 PFLOPS |
| 数据来源:技术白皮书 |
制药领域:与阿斯利康合作,将分子动力学模拟从1年压缩至2天,加速新药研发周期。
语言模型:G42集团采用CS-3集群,构建24万亿参数模型,单日可微调700亿参数的Llama 2。
医疗诊断:梅奥诊所利用其系统,开发出可解析千万级医学影像的AI助手,诊断准确率提升41%。
“我们的系统就像给AI工程师装上了火箭推进器!”——Cerebras CTO Sean Lie在Hot Chips大会上的这句调侃,恰如其分地诠释了其技术优势。更令人咋舌的是,用户代码量竟比传统方案减少97%,开发者再也不用被分布式计算的”魔鬼细节”折磨!
专家观点:

竞品参数对比(2025 Q1):
| 指标 | Cerebras WSE-3 | NVIDIA H100 | Groq LPU |
|---|---|---|---|
| 单芯片算力 | 125 PFLOPS | 4 PFLOPS | 1.5 PFLOPS |
| 训练速度(GPT-4) | 1.2天 | 6.8天 | 不支持 |
| 能效比(FLOPS/W) | 8.7 | 3.2 | 5.1 |
| 最大集群规模 | 2048节点 | 4096节点 | 512节点 |
| 数据来源:行业分析报告 |
尽管性能碾压,Cerebras也面临”甜蜜的烦恼”——83%收入依赖G42等大客户,且IPO估值从预期的80亿美元回调至40亿美元。不过,随着与高通合作推出推理加速方案,其技术护城河正从训练向全栈延伸。
“生成式AI的决胜点已从训练转向推理!”CEO Andrew Feldman的预判,正在被其最新成果验证:
更值得期待的是,其秘密武器SwarmX互连技术,可通过光纤连接192个CS-3,构建EB级内存池——这相当于把整个互联网的图书内容同时塞进AI大脑!
话说回来,这家”硅谷狂人”能否真正撼动英伟达的霸主地位?答案或许藏在两个细节里:其一,他们的良品率竟比传统芯片厂还高;其二,AMD前CTO Lauterbach坐镇研发——要知道,当年SeaMicro被AMD收购时,可是埋下了反超x86架构的火种。这场算力战争的好戏,才刚刚拉开帷幕!







识别右侧二维码,进入阅读全文