
cogvlm2-llama3-caption
清华THUDM开源的多模态视频理解模型,为视频内容提供专家级文本描述
特别提示:根据ComfyUI-AnimateDiff-Evolved的README,商业用途得额外授权。想靠这个接单的同学记得走官方渠道申请license!
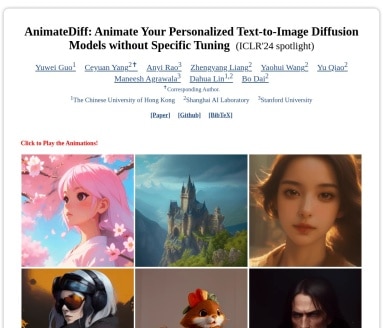
现在说自己是AI工具不稀奇,但第一次看到AnimateDiff的操作流程时——好家伙,这玩意儿简直像给图片打了一管鸡血!它能用Stable Diffusion这类模型生成的静态画面,两三下就变成活灵活现的动画视频。最关键的是不用针对每个换皮模型做专门训练,直接把运动模块往上怼就行。
| 对比项 | AnimateDiff | 传统方法 |
|---|---|---|
| 模型适配时间 | <5分钟 | 2-3天 |
| 硬件成本 | 中端显卡能跑 | 专业渲染农场 |
| 风格切换速度 | 切换模型即生效 | 重新训练参数 |
说实在的,这项目开源良心到想给作者打钱——GitHub仓库全套代码直接放送,ModelScope上还能捡到现成模型。不过自己部署就像玩俄罗斯方块,得一个个安装:
animatediff create -m model_name调教参数要是嫌麻烦,PromptBase上有些开发者卖整合包,价格从9.9美元到199美元都有,这水可深着呐。某宝搜”AnimateDiff懒人包”能看到各种神奇版本,不过友情提示——遇到说包教包会的卖家,记得先看买家秀!
试过官方推荐的进化版插件后发现,那些”enhanced sampling”功能确实能出电影级转场,但代价是显存占用暴涨30%。更绝的是和ControlNet联动的效果,让这只二哈在不同场景间丝滑切换(虽然AI还是看不懂沙发为啥不能长在树上)。
作为ICLR2024的焦点论文,AnimateDiff在TXYZ.ai的学术圈子里讨论度爆表。看论文里的技术路线才明白,人家的motion module训练时用了超30万条视频片段,难怪能学出”物体运动就该这么动”的直觉。不过实际体验中发现,像水面反光这种细节还是会有抽帧感,期待后面出的v2版能优化这部分。
测试过十几种模型后发现,RCNZ Cartoon 3D的输出最稳定,而majicMIX虽然效果炸裂,但生成时间要多等两分钟——鱼和熊掌的问题在AI界也躲不过啊…








识别右侧二维码,进入阅读全文